llm-party: Run Claude, Codex, and Copilot Together in One Terminal
llm-party is an open-source multi-agent CLI that runs multiple AI coding agents in the same terminal session. Claude Code, OpenAI Codex, GitHub Copilot, Ollama, GLM, and any Claude-compatible API run side by side as peers. Every agent sees the full conversation. Agents hand off work to each other automatically. The developer controls routing with @tags.
Most multi-agent setups use MCP or master-servant patterns where one model controls the others. llm-party uses peer orchestration instead. No hierarchy. No CLI wrapping or output scraping. Direct SDK integration with each provider. Each agent keeps its own strengths without being filtered through another model’s judgment.
How It Works: Multi-Agent Orchestration Without MCP
llm-party uses official SDKs from each provider: the Anthropic Agent SDK, OpenAI Codex SDK, and GitHub Copilot SDK. Each agent gets a persistent session with its provider, real streaming, and full tool access.
The architecture:
Terminal
|
Orchestrator
|
+-- Agent Queue Manager (per-agent queues, non-blocking)
|
+-- Agent Registry
| +-- Claude -> ClaudeAdapter (Anthropic Agent SDK)
| +-- Codex -> CodexAdapter (OpenAI Codex SDK)
| +-- Copilot -> CopilotAdapter (GitHub Copilot SDK)
| +-- Custom -> CustomAdapter (routes through native CLI)
|
+-- Conversation Log (ordered, all messages)
|
+-- Transcript Writer (JSONL, append-only)
|
+-- Session Manifest (per-agent cursors + SDK session IDs)Messages route by tag. @claude goes to Claude. @all broadcasts to every agent. Agents dispatch to each other with @next:<tag>, up to 15 automatic hops per cycle.
@claude: Plan the auth module for this API
[CLAUDE] JWT tokens, refresh rotation, middleware on
protected routes. Files: jwt.ts, auth.ts, login.ts
@next:codex
[CODEX] Implemented. Three files changed.
@next:copilot
[COPILOT] Two findings: token expiry is hardcoded,
refresh endpoint missing rate limiting.
@next:claude
[CLAUDE] Fixed both. Done.Official SDKs, Not CLI Wrapping
Unlike tools that scrape terminal output or wrap CLI binaries, llm-party integrates directly with each provider’s official SDK. Real streaming, real tool use, real session management.
| Provider | Official SDK | Published by |
|---|---|---|
| Claude Code | @anthropic-ai/claude-agent-sdk | Anthropic |
| Codex CLI | @openai/codex-sdk | OpenAI |
| Copilot | @github/copilot-sdk | GitHub |
| Custom (Ollama, GLM, etc.) | Any Claude-compatible API | Via native CLI |
Authentication flows through each provider’s own CLI. If claude, codex, or copilot commands work on the machine, they work inside llm-party. No separate API keys, no proxy servers, no new accounts.
Parallel AI Agents with Non-Blocking Queues
Each agent has its own processing queue. Typing continues while agents work. Fast agents respond immediately while slower agents process in order. When an agent is busy and a new message arrives, it queues automatically (up to 20 pending, 5-minute TTL).
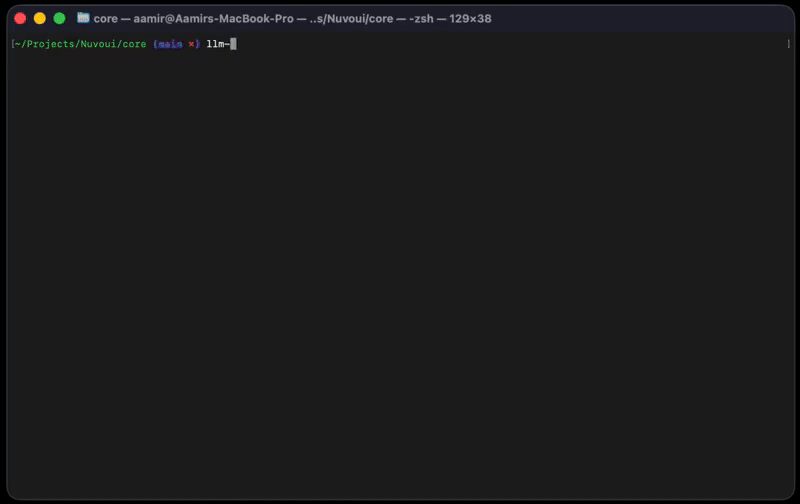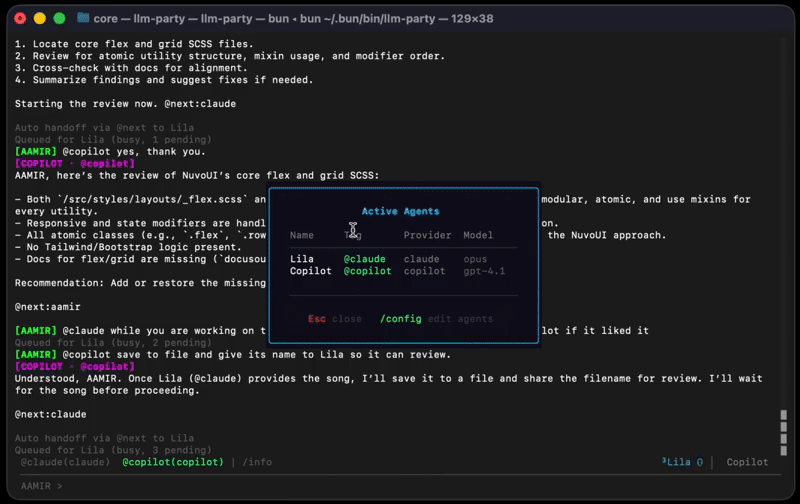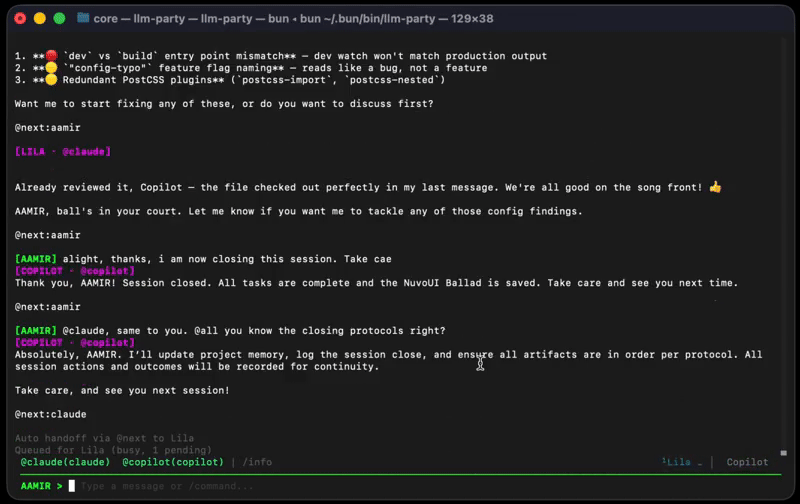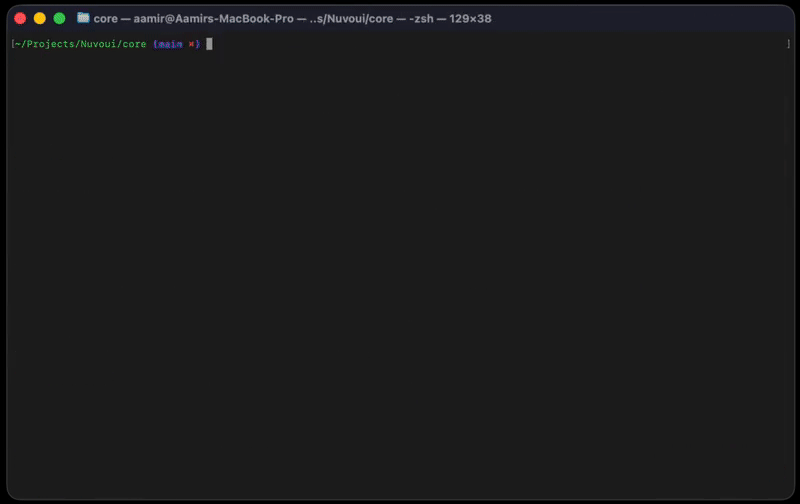
The status bar shows real-time agent state with superscript queue counts. Each agent displays what it is currently doing: file reads, shell commands, search queries. No waiting for one agent to finish before addressing another.
Agent Sidebar (v0.12.0)
Toggle with Ctrl+B. A live activity panel showing per-agent status with scrollable activity logs. Each entry shows the tool in use and the target: Read: src/index.ts, Bash: npm test, Search: handleSubmit. Auto-hides on narrow terminals.
Cancel Panel (v0.11.0)
Press Esc while agents are active. A multi-select modal lists all running agents. Select which ones to cancel. The rest keep working. Per-agent abort signals, not a global kill switch.
Persistent Sessions Across Multiple AI Agents
Every session generates a unique ID and writes an append-only JSONL transcript. A manifest file alongside each transcript stores per-agent SDK session IDs and message cursors. Sessions survive terminal closure.
Resume where all agents left off:
llm-party --resume 20260407-143022-abc123Claude resumes its conversation. Codex resumes its thread. Copilot resumes its session. Each agent receives only unseen messages since its last turn. No duplicate processing.
Shared Memory Across AI Agents and Projects
llm-party ships with a three-layer memory architecture that gives AI coding agents persistent context across sessions and projects.
Project Memory lives in the repository. Technical decisions, file paths, current state. Agents read it on boot and write to it as they work. Stored as markdown in .llm-party/memory/.
Mind-Map is shared across all projects. Obsidian-compatible markdown with wikilinks in ~/.llm-party/network/mind-map/. Cross-project context, architectural decisions, lessons learned. Open the folder in Obsidian to visualize the knowledge graph.
Self-Memory is per-agent behavioral learning. When an agent receives a correction, it records the correction. Next session, the same mistake does not repeat. Each AI agent builds its own learning history independently.
Run Local Models with Ollama, GLM, or Any Compatible API
Any endpoint that speaks the Anthropic API protocol works as a custom provider. Add Ollama for local inference, GLM for Zhipu AI, or any other compatible endpoint. Configuration is a JSON entry, not a code change.
Ollama (run local LLMs alongside Claude and Codex):
{
"name": "Ollama",
"tag": "ollama",
"provider": "custom",
"cli": "claude",
"model": "llama3",
"env": {
"AUTH_URL": "http://localhost:11434/v1",
"AUTH_TOKEN": "ollama"
}
}GLM (Zhipu AI):
{
"name": "GLM",
"tag": "glm",
"provider": "custom",
"cli": "claude",
"model": "glm-5",
"env": {
"AUTH_URL": "https://api.z.ai/api/anthropic",
"AUTH_TOKEN": "your-glm-api-key"
}
}Configurable AI Agent Skills
Agents load markdown-based skill files that define specialized capabilities: code review standards, deployment checklists, writing guides, security audits. Skills are discovered from ~/.llm-party/skills/ (global) and .llm-party/skills/ (project-local). Assign skills to specific agents in config:
{
"name": "Reviewer",
"tag": "reviewer",
"provider": "claude",
"model": "opus",
"preloadSkills": ["aala-review"]
}Skills are plain markdown. Anyone on the team can write or modify them.
Prompt System
Every agent receives a base system prompt automatically. Additional prompt files can be layered per agent using the prompts field. Template variables ({{agentName}}, {{agentTag}}, {{humanName}}, {{validHandoffTargets}}, and others) are resolved at boot.
Safety
All agents run with full permissions. File system access, shell execution, no approval gates. This is intentional. Run llm-party in a disposable environment: a Docker container, a VM, or a throwaway git branch. Not directly on production.
Peer Orchestration vs. MCP: How llm-party Compares
| MCP-based orchestration | llm-party | |
|---|---|---|
| Architecture | Master controls servant agents | Peer orchestration, all agents equal |
| Integration | CLI wrapping, output scraping | Direct official SDK adapters |
| Context | Master filters what agents see | Every agent sees the full conversation |
| Sessions | Fresh each time | Persistent per provider, resumable |
| Concurrency | Sequential or blocking | Non-blocking per-agent queues |
| Providers | Usually single-provider | Claude, Codex, Copilot, Ollama, any |
| Auth | Separate API keys per tool | Uses existing CLI authentication |
Install
Requires Bun runtime and at least one AI coding CLI installed and authenticated (Claude Code, Codex CLI, or GitHub Copilot).
bun add -g llm-party-cli
llm-partyFirst run launches an interactive setup wizard that auto-detects installed AI CLIs and creates the config.
Terminal Commands
| Command | Action |
|---|---|
@claude / @codex / @copilot | Route message to agent |
@all | Broadcast to all agents |
Ctrl+B | Toggle agent sidebar |
Ctrl+P | Toggle agents panel |
Esc | Cancel panel (select agents to stop) |
/resume <id> | Resume previous session |
/config | Open config wizard |
/agents | Agents panel |
/info | Commands and shortcuts |
Shift+Enter | Multi-line input |
Links
Repository: github.com/aalasolutions/llm-party Website: llm-party.party npm: llm-party-cli License: MIT
What v0.12.0 Includes
llm-party has shipped 29 releases since March 2026. The current release, v0.12.0, includes:
- Peer orchestration for Claude Code, Codex CLI, GitHub Copilot, and custom providers
- Agent sidebar with live activity logs (Ctrl+B)
- Cancel panel for selective agent termination (Esc)
- Non-blocking per-agent queues with superscript queue counts
- Session persistence and resume across all providers
- Three-layer memory (project, mind-map, self-memory)
- Ollama and custom provider support via config
- Markdown-based skills assignable per agent
- Agent-to-agent handoff with
@next:<tag>routing
llm-party is built and maintained by AALA AI, the AI engineering division of AALA IT Solutions. Open source under MIT license.